caffe中的卷积操作的思想是利用矩阵相乘来实现的。
设一副图像尺寸为MxM,卷积核mxm。在计算时,卷积核与图像中每个mxm大小的图像块相乘,相当于把该mxm图像块提取出来,表示成一个长度为m^2的列,在pad=0,stride=1的情况下,一共有(M-m+1)^2个,把这么些个图像块均表示为m^2的列,然后组合为一个大矩阵(m^2 x (M-m+1)^2)。然后把卷积核也表示为m^2向量,并按列复制为同尺寸矩阵(m^2 x (M-m+1)^2)。俩矩阵按列做点积即得结果。
上面这部分叙述就是im2col_cpu这个函数做的事,举例来说,一张2828的图像,20个55的卷积核,pad=0,stride=1,那么上面函数中的height_col和width_col的值都是24,channels_col = 155 = 25,所以可以得到data_col的大小为252424 = 14400。他的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
Dtype* data_col) {
const int height_col = (height + 2 * pad_h - kernel_h) / stride_h + 1;
const int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
const int channels_col = channels * kernel_h * kernel_w;
for (int c_col = 0; c_col < channels_col; ++c_col) {
int w_offset = c_col % kernel_w;
int h_offset = (c_col / kernel_w) % kernel_h;
int c_im = c_col / kernel_h / kernel_w;
for (int h_col = 0; h_col < height_col; ++h_col) {
for (int w_col = 0; w_col < width_col; ++w_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
int w_im = w_col * stride_w - pad_w + w_offset;
data_col[(c_col * height_col + h_col) * width_col + w_col] =
(h_im >= 0 && w_im >= 0 && h_im < height && w_im < width) ?
data_im[(c_im * height + h_im) * width + w_im] : 0;
}
}
}
}
论文笔记 《Fast Search in Hamming Space with Multi-Index Hashing》
这篇论文的下载地址,这篇论文主要解决的是在汉明空间上的r-neighbors of query和K-NN query,提出了一种新型的多分段索引哈希方法,比传统的linear scan的速度快了100倍。
1.多分段索引哈希
它的主要思想是:
对于一个哈希码h,一共有b位,将它分为m段,那么,每段的长度为$\lfloor b/m\rfloor$或者$\lceil b/m \rceil$,为了方便起见,我们假设b能够被m整除,下位直接用$b/m$代替,那么当两个哈希码h和g的汉明距离为r bits的时候,在这m段哈希码中必然至少存在一段,它们之间的汉明距离最多为$\lfloor r/m \rfloor$。
那么基于这个思想,我们可以在查询与哈希码h的汉明距离为r的所有哈希码时,我们可以分别对这m段哈希码进行查找,找出在每一段哈希码中,汉明距离小于$\lfloor r/m \rfloor$的查询结果,将m段的查询结果合并之后就是我们最终的候选集,最后在候选集中筛选出汉明距离大于r的结果。这种方法相比于线性搜索的需要查找$L(b,r)$个桶的情况,现在我们只需要搜索$m*L(b/m,\lfloor r/m \rfloor)$个哈希桶,大大提高了查询效率。
Simhash算法原理
这篇文章简单的对simhash做个记录,因为已经有很多文章都写的非常好了,类似参考文献1和参考文献2,simhash是当年google用来文本去重的算法,大致思想就是将一个文档转换成一个n位的字节,然后判断两篇文章的字节码的汉明距离,如果小于某个给定的阈值就说明它们两个相似。那么由此可以看出,它分为两个部分,一个是n位字节码的生成,另一个是汉明距离的比较。
1.特征字节的生成
引用这张经典的原理图:
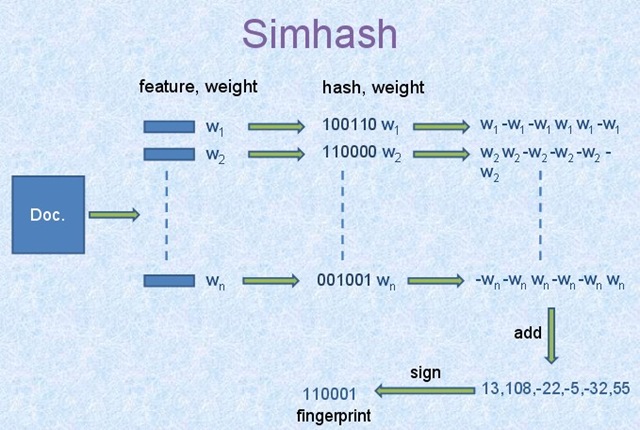
它的算法流程如下:
1.选择simhash的位数,例如32位或64位;
2.将Doc文件进行分词,并赋予权重,赋予权重的方法有很多重,可以根据词频等信息的一些方法。将每个关键词转换为对应位数的哈希码,在这里,我们假设我们的哈希位数为6,那么依据图中信息可知n个词的哈希码如上面100110,110000…;
3.然后对这n个哈希码按列相加,如果哈希码为1,那么+weight,反之-weight,计算最后生成的结果,如上图所示的[13,108,-22,-5,-32,55];
4.然后由[13,108,-22,-5,-32,55]转换成最终的哈希码[1,1,0,0,0,1],正取1,负取0。
好,以上就是我们生成哈希码的过程,那么得到哈希码之后,如何从海量文本中查询汉明距离为r的文本呢?