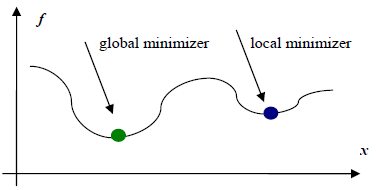
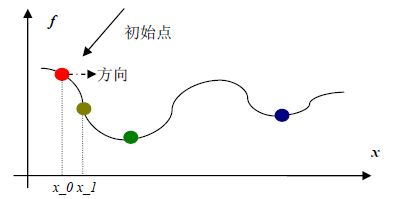
上一篇文章介绍了梯度下降相关的优化方法,这一篇来介绍一个在优化领域也用的非常多的方法,牛顿法和拟牛顿法
0.Hesse 矩阵
Hesse矩阵在牛顿法中常被用到,它的本质就是二维偏导的矩阵,形式如下所示:

1.牛顿法
之前介绍的梯度下降法,只考虑了目标函数的一阶导数信息,而牛顿法择一并考虑二阶导数信息。
设$f(x)$为具有二姐连续偏导数的目标函数,第$k$次迭代值为$x_k$,在$x_k$处进行二阶泰勒展开:
$$f(x)=f(x_k)+g_k^T(x-x_k)+\frac{1}{2}(x-x_k)^TH(x_k)(x-x_k)$$
$g_k$是$f(x)$的梯度向量在点$x_k$处的值,$H(x_k)$是$f(x)$的Hesse矩阵在点$x_k$处的值。
由于极小值点必然是一阶导数为0的点,所以我们令$f(x)$的一阶导数等于0,求上面那个泰勒展开式的导数:
$$\nabla{f(x)}=g_k+H_k(x-x_k)$$