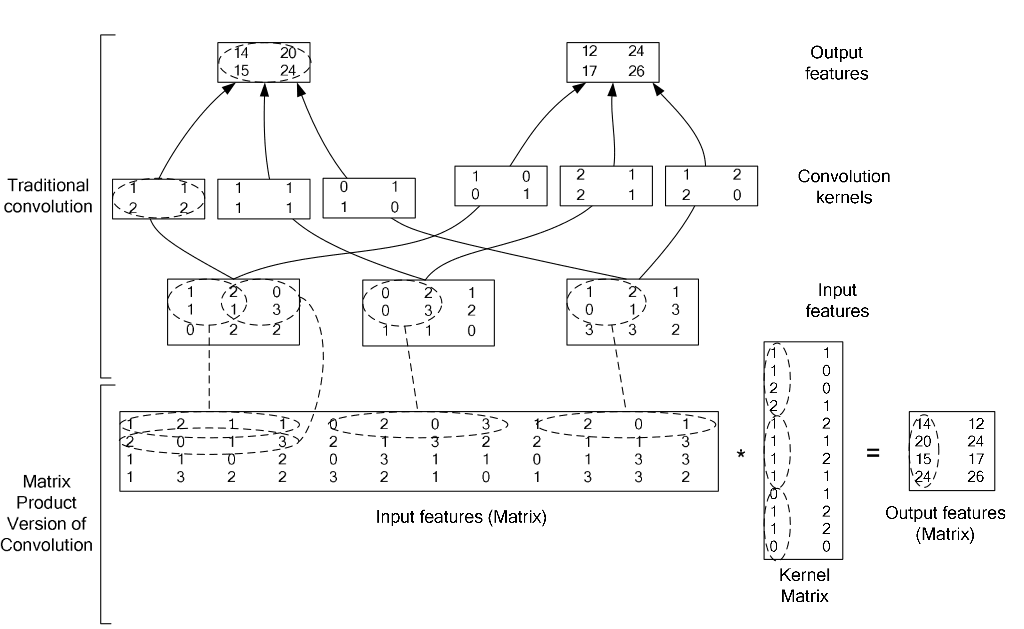
caffe中的卷积操作的思想是利用矩阵相乘来实现的。
设一副图像尺寸为MxM,卷积核mxm。在计算时,卷积核与图像中每个mxm大小的图像块相乘,相当于把该mxm图像块提取出来,表示成一个长度为m^2的列,在pad=0,stride=1的情况下,一共有(M-m+1)^2个,把这么些个图像块均表示为m^2的列,然后组合为一个大矩阵(m^2 x (M-m+1)^2)。然后把卷积核也表示为m^2向量,并按列复制为同尺寸矩阵(m^2 x (M-m+1)^2)。俩矩阵按列做点积即得结果。
上面这部分叙述就是im2col_cpu这个函数做的事,举例来说,一张2828的图像,20个55的卷积核,pad=0,stride=1,那么上面函数中的height_col和width_col的值都是24,channels_col = 155 = 25,所以可以得到data_col的大小为252424 = 14400。他的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void im2col_cpu(const Dtype* data_im, const int channels,
const int height, const int width, const int kernel_h, const int kernel_w,
const int pad_h, const int pad_w,
const int stride_h, const int stride_w,
Dtype* data_col) {
const int height_col = (height + 2 * pad_h - kernel_h) / stride_h + 1;
const int width_col = (width + 2 * pad_w - kernel_w) / stride_w + 1;
const int channels_col = channels * kernel_h * kernel_w;
for (int c_col = 0; c_col < channels_col; ++c_col) {
int w_offset = c_col % kernel_w;
int h_offset = (c_col / kernel_w) % kernel_h;
int c_im = c_col / kernel_h / kernel_w;
for (int h_col = 0; h_col < height_col; ++h_col) {
for (int w_col = 0; w_col < width_col; ++w_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
int w_im = w_col * stride_w - pad_w + w_offset;
data_col[(c_col * height_col + h_col) * width_col + w_col] =
(h_im >= 0 && w_im >= 0 && h_im < height && w_im < width) ?
data_im[(c_im * height + h_im) * width + w_im] : 0;
}
}
}
}
这个函数根据参数名比较好懂,知道了这个思想之后,我们来一步步的看下去,首先是forward函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
这个weight数组的weight_size = 卷积核个数*卷积核width*卷积核height,num_为batch_size的值。这个函数比较好理解,分别对batch批次图片进行卷积操作,forward_cpu_gemm 是计算 weight与图片之间进行相乘,如果有偏置项的话,那么 forward_cpu_bias就是在刚才计算的基础上再加一个偏置,下面我们来看一看forward_cpu_gemm函数做了一些什么:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void BaseConvolutionLayer<Dtype>::forward_cpu_gemm(const Dtype* input,
const Dtype* weights, Dtype* output, bool skip_im2col) {
const Dtype* col_buff = input;
if (!is_1x1_) {
if (!skip_im2col) {
conv_im2col_cpu(input, col_buffer_.mutable_cpu_data());
}
col_buff = col_buffer_.cpu_data();
}
for (int g = 0; g < group_; ++g) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, conv_out_channels_ /
group_, conv_out_spatial_dim_, kernel_dim_,
(Dtype)1., weights + weight_offset_ * g, col_buff + col_offset_ * g,
(Dtype)0., output + output_offset_ * g);
}
}
在这个函数中,weight_offset_ = channels*卷积核个数*卷积核width*卷积核height,col_offset_的值就是我在im2col_cpu中计算的data_col的大小,output_offset_ = 卷积核个数*卷积后的图片宽度*卷积后的图片长度。conv_im2col_cpu这个函数里面是直接调用了我最上面提到的im2col_cpu函数,我也把代码贴一下吧:1
2
3
4
5
6
7
8
9
10
11
12
13inline void conv_im2col_cpu(const Dtype* data, Dtype* col_buff) {
if (!force_nd_im2col_ && num_spatial_axes_ == 2) {
im2col_cpu(data, conv_in_channels_,
conv_input_shape_.cpu_data()[1], conv_input_shape_.cpu_data()[2],
kernel_shape_.cpu_data()[0], kernel_shape_.cpu_data()[1],
pad_.cpu_data()[0], pad_.cpu_data()[1],
stride_.cpu_data()[0], stride_.cpu_data()[1], col_buff);
} else {
im2col_nd_cpu(data, num_spatial_axes_, conv_input_shape_.cpu_data(),
col_buffer_shape_.data(), kernel_shape_.cpu_data(),
pad_.cpu_data(), stride_.cpu_data(), col_buff);
}
}
而那个group循环是用来做group convolution的,默认group_的值为1,不过据caffe作者自述,group convolution是没什么用的,大家只需要知道,在这里,只会循环一次即可。
那么在caffe_cpu_gemm里面到底又做了些什么呢?
1 | void caffe_cpu_gemm<double>(const CBLAS_TRANSPOSE TransA, |
这个函数的作用就是将刚才在im2col_cpu中生成的data_col数组调用 cblas_dgemm 函数转换为矩阵相乘。
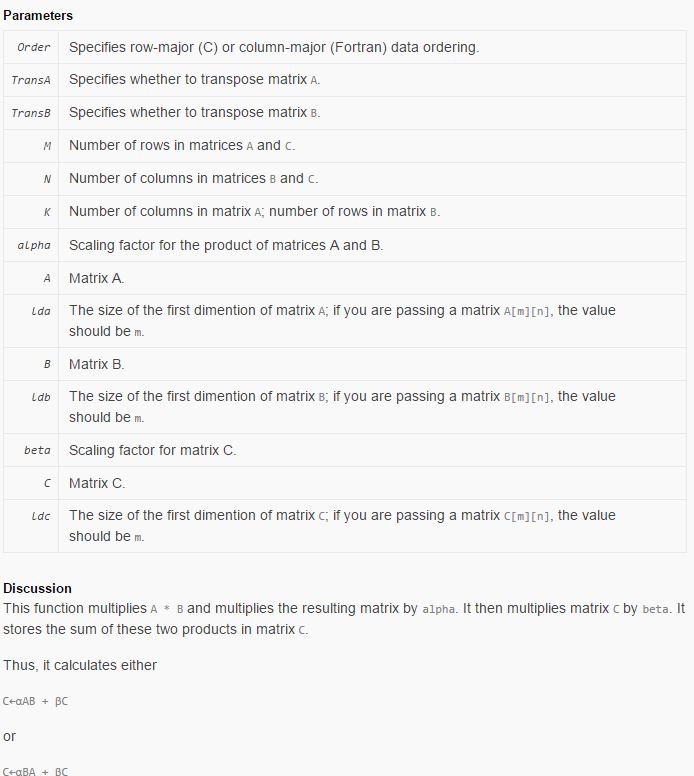
对参数说明一下,TransA和TransB都是CblasNoTrans,可知lda = K,ldb = N,M的值为num_output,即为卷积核的个数,N为out_put_size,即为经过卷积之后图片的尺寸,K=channels kernel_h kernel_w,就是我们在im2col_cpu函数中计算的channels_col值,可以把它理解为一个三维的卷积核的大小,alpha为1,A为weights,B为在im2col_cpu中计算的data_col,C就是计算后的值,而cblas_dgemm函数就是将A和B数组转换为KN和KN的矩阵做点积运算,A为参数矩阵,是将M个channels kernel_h kernel_w的三维卷积核拉成一个列向量,然后复制N个列向量组成A,B为channels个图像待卷积的小块都转换成列向量而组成的,C就是卷积之后的结果,也为K*N。cblas_dgemm函数是blas的一个函数,这里简单的给出它的一些说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Declaration
SWIFT
func cblas_dgemm(_ Order: CBLAS_ORDER,
_ TransA: CBLAS_TRANSPOSE,
_ TransB: CBLAS_TRANSPOSE,
_ M: Int32,
_ N: Int32,
_ K: Int32,
_ alpha: Double,
_ A: UnsafePointer<Double>,
_ lda: Int32,
_ B: UnsafePointer<Double>,
_ ldb: Int32,
_ beta: Double,
_ C: UnsafeMutablePointer<Double>,
_ ldc: Int32)
OBJECTIVE-C
void cblas_dgemm ( const enum CBLAS_ORDER __ Order , const enum CBLAS_TRANSPOSE __ TransA , const enum CBLAS_TRANSPOSE __ TransB , const int __ M , const int __ N , const int __ K , const double __ alpha , const double *__ A , const int __ lda , const double *__ B , const int __ ldb , const double __ beta , double *__ C , const int __ ldc );
以上所述就是caffe中的卷积操作,这里还有一张图,可以更好的辅佐理解一下