论文地址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn
这段时间,让师弟研究了下RCNN的内容,我自己也看了一下,对RCNN的三大系列(还有Fast RCNN,Faster RCNN)做了一些了解,在这里简单做个笔记。
1.整体构思
RCNN是目前目标检测这个task里可以说是最著名的了,包括后面的fast-rcnn和faster-rcnn都是同一个作者提出来的,使目标检测的实时性成为了可能。它的主要框架图是:

可以看出它的框架组成:
1.用selective search方法划分2k-45k个region;
2.分别对每个region提取特征,最后将提取到的特征送到k(k的取值与类别数相等)个svm分类器中识别以及送到一个回归器中去调节检测框的位置;
3.将k个SVM分类器中得分最高的类作为分类结果,将所有得分都不高的region作为背景;
4.通过回归器调整之后的结果即为检测到的位置。
2.模型设计
2.1 Region proposals
这一部分就是利用selective search的方法来划分region,selective search方法是一个语义分割的方法,它通过在像素级的标注,把颜色、边界、纹理等信息作为合并条件,多尺度的综合采样方法,划分出一系列的区域,这些区域要远远少于传统的滑动窗口的穷举法产生的候选区域。如下图所示:

2.2 特征提取
通过训练好的Alex-Net,先将每个region固定到227*227的尺寸,然后对于每个region都提取一个4096维的特征。作者提到了一点是在resize到227*227的过程中,在region外面扩大了一个16个宽度的边框,region的范围也就相应扩大,,考虑了更多的背景信息。作者在论文后面的Appendix A也有讨论。
3.模型训练
3.1 CNN训练
首先拿到Alex-Net在imagenet上训练的CNN作为pre-train,然后将该网络的最后一个fc层的1000改为N+1(N为类别的数目,1是加一个背景)来fine-tuning用于提取特征的CNN。作者将大于0.5的IOU作为正样本,小于0.5的作为负样本,调整学习率为原来的1/10,对于每个batch-size = 128,32个为正样本,96个位负样本。
3.2 分类器训练
训练N(N为类别数)个lsvm分类器,分别对每一类做一个二分类,在这里,作者是将大于0.5的IOU作为正样本,小于0.3的IOU作为负样本,至于为啥这里不是0.5,当设置为0.5的时候,mAp下降5%,设置为0的时候下降4%,最后取中间0.3。作者在后面的Appendix B中有讨论,并且说softmax在VOC 2007上测试的mAP违纪50.9%,没有svm的54.2%的效果好。为啥呢?作何讨论说,因为softmax的负样本(也可以理解为背景样本)是随机选择的即在整个网络中是共享的,而svm的负样本是相互独立的,每个类别都分别有自己的负样本,svm的负样本更加的“hard”,所以svm的分类的准确率更高。
3.3 Boundingbox Regression
这一部分,作者是通过训练一个回归器来对region的范围进行一个调整,毕竟region最开始只是用selective search的方法粗略得到的,通过调整之后得到更精确的位置。
4.结果
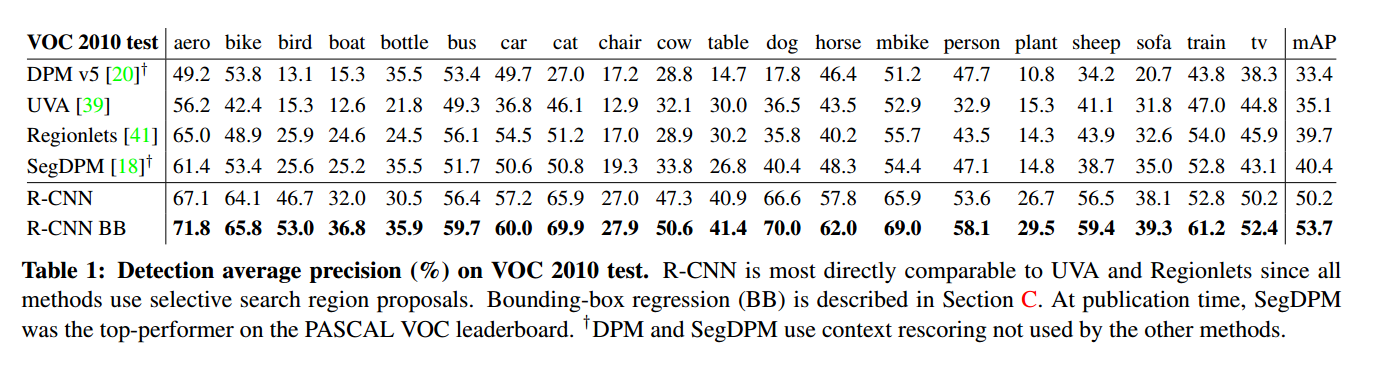
在PASCAL VOC2010-12上的结果
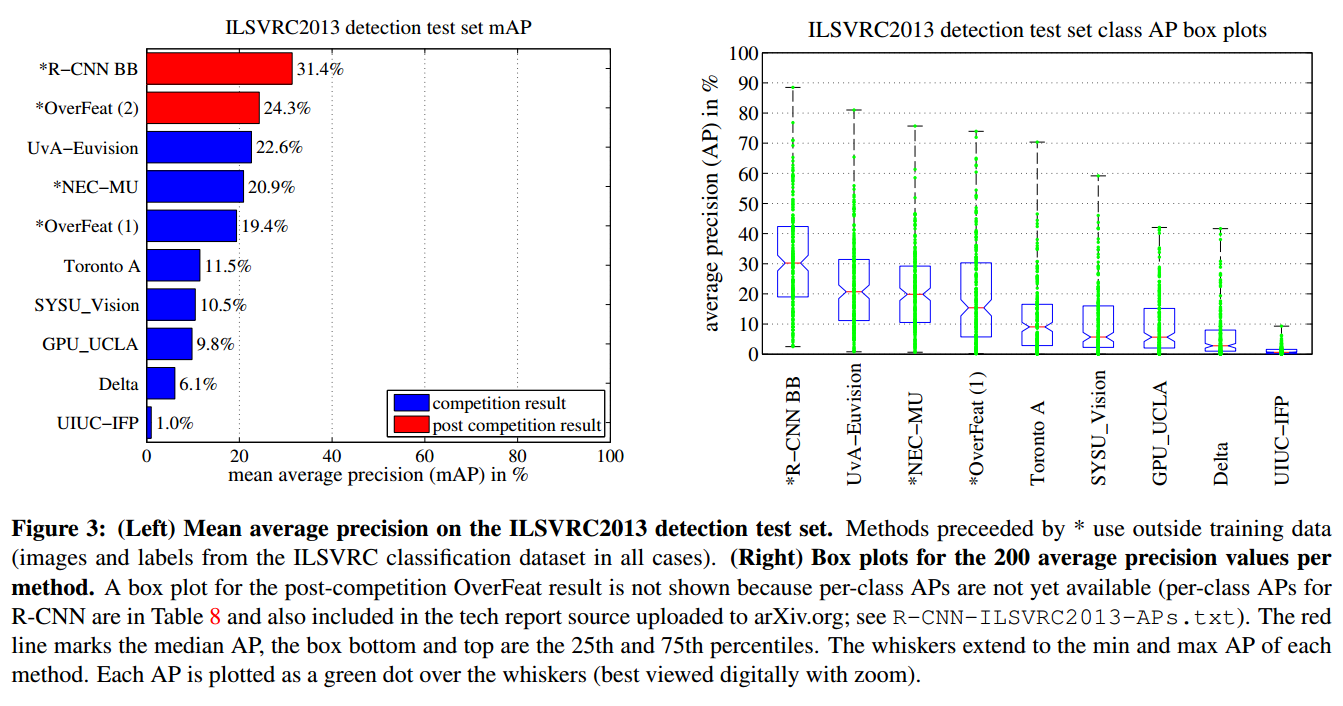
在ILSVRC13上的结果
5.Visualization and ablation
5.1 Visualization
在这里,作者是用pool5的特征来做可视化的,根据前面层的一些参数计算可知,p5层的一个单元是对应到227*227中原图的一个195*195的感受野,作者采用的可视化方法就是将10million个已经训练好的region做一个前向,用nonmaximum方法,并按照置信度分数排序,然后对应到原图中的单元中,看网络学到了什么,下图就是可视化的结果:

5.2 ablation
这是一些对比分析的实验结果:
1.Performance layer-by-layer, without fine-tuning
这个对比试验就是上图中的前三行,分别是用pool5,fc6和fc7这三层的特征做分类,结果都差不多,而且pool6的结果还比pool7的结果好,作者就得出结论是:CNN的特征表达一般是在卷积层。
2.Performance layer-by-layer, with fine-tuning
这个对比试验就是上图中的第4-6行,分别是pool5,fc6和fc7经过finetuning之后的结果,由上图可以看出,pool5经过finetuning之后,mAP的提高不大,所以可以说明卷积层提取出来的特征是更具有泛化性的,而fc7经过finetuning之后的提升最大,说明finetuning主要作用于全连接层。
3.Comparison to recent feature learning methods
这个对比试验就是上图中的最后三行,对比的是其他的特征,明显可以看出,CNN的特征学习能力比其他的方法要好。