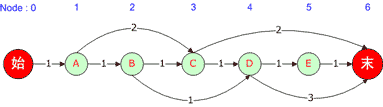
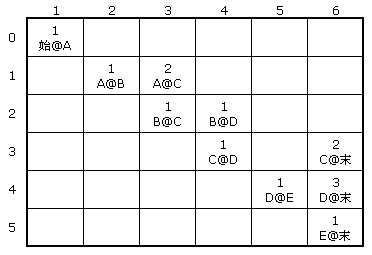
在研究分词的这段时间里,接触了隐马尔科夫模型(Hidden Markov Model,HMM),刚开始看的时候一头雾水,花了两天时间静下心来研究了一下,在此做个总结。
一、介绍
我们通常都习惯寻找一个事物在一段时间里的变化模式(规律)。这些模式发生在很多领域,比如计算机中的指令序列,句子中的词语顺序和口语单词中的音素序列等等,事实上任何领域中的一系列事件都有可能产生有用的模式。
考虑一个简单的例子,有人试图通过一片海藻推断天气——民间传说告诉我们‘湿透的’海藻意味着潮湿阴雨,而‘干燥的’海藻则意味着阳光灿烂。如果它处于一个中间状态(‘有湿气’),我们就无法确定天气如何。然而,天气的状态并没有受限于海藻的状态,所以我们可以在观察的基础上预测天气是雨天或晴天的可能性。另一个有用的线索是前一天的天气状态(或者,至少是它的可能状态)——通过综合昨天的天气及相应观察到的海藻状态,我们有可能更好的预测今天的天气。
首先,我们将介绍产生概率模式的系统,如晴天及雨天间的天气波动。
然后,我们将会看到这样一个系统,我们希望预测的状态并不是观察到的——其底层系统是隐藏的。在上面的例子中,观察到的序列将是海藻而隐藏的系统将是实际的天气。
最后,我们会利用已经建立的模型解决一些实际的问题。对于上述例子,我们想知道:
- 给出一个星期每天的海藻观察状态,之后的天气将会是什么?
- 给定一个海藻的观察状态序列,预测一下此时是冬季还是夏季?直观地,如果一段时间内海藻都是干燥的,那么这段时间很可能是夏季,反之,如果一段时间内海藻都是潮湿的,那么这段时间可能是冬季。