(一)、人名的自动识别
中国人名识别的主要困难有:
- 人名构成的多样性
如:姓名,有名无姓,有姓无名,姓+前后缀,港澳台已婚妇女姓名 - 人名内部相互成词
如:王国维,高峰,汪洋,张朝阳 - 人名与其上下文组成合成词
如:“这里有关天陪的壮烈事迹” - 歧义理解
如:“周鹏和同学”存在“周鹏”、“周鹏和”的歧义
针对这个问题目前存在的主要解决方案有:规则方法,统计方法以及规则和统计相结合的方法。规则方法主要利用了姓氏分类和名字组成的限制性,如名字的组成一般不会超过四个字。但是由于它需要“单点激发”,即它需要扫描到姓氏、职衔、称呼后才开始识别,所以往往无法识别不具有明显特征的人名,例如“有名无姓”的情况。统计方法主要是针对姓名语料库来训练某个字作为姓名组成部分的概率,并利用它们来计算某个字段作为姓名的概率值,其中概率值大于某一阈值的字段识别为中国人名。统计方法对语料库的规模要求很高。所以,在这种情况下,提出了基于角色标注的中文人名自动识别算法。该方法的大致思路是用隐马尔科夫模型(HMM)在分词结果上标注人名构成的角色,然后在标注出的角色序列基础上根据各个不同的角色,进行最长模式匹配,最终识别出人名。下面分别来说明这几个步骤:
1.标注人名构成的角色
角色标注相当于是在已经粗分好的结果上标注出各个词的词性,只不过此时的词性不再是动词、名词、形容词等,而是针对它们和人名的关系划分为人名的内部组成、上下文、无关词。具体的角色分类如表1 所示。
表1 中国人名的构成角色
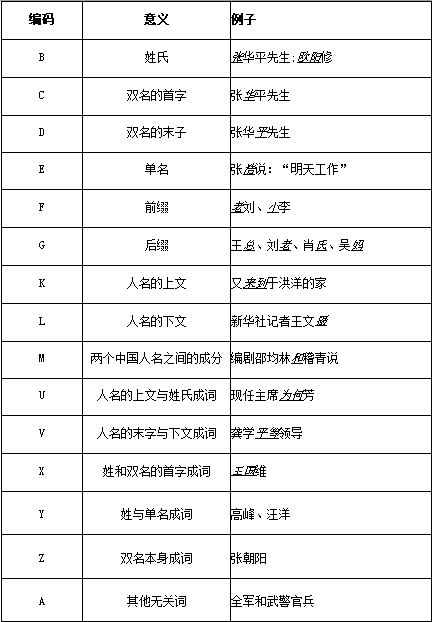
根据该表,对切分结果“馆/内/陈列/周/恩/来/和/邓/颖/超生/前/使用/过/的/物品”进行角色标注,其结果为:“馆/A 内/A 陈列/K 周/B 恩/C 来/D 和/M邓/B 颖/C 超生/V 前/A 使用/A 过/A 的/A 物品A”(“周”、“邓”是姓氏标为B,“恩”、“颖”是双名首字标为C,“来”是双名末字标为D,“和”是两个人名之间的连接词标为M,“超”字和后面的“生”字因为组成了一个词语所以标为V)。
那么如何自动进行角色标注呢?
这里我们采用了viterbi 算法,也就是说从所有可能的标注结果中选出概率最大者作为最终标注结果。具体推导过程如下:
假定 W 是 Token 序列(即粗分后得到的序列)
T 是 W 某个可能的角色标注序列
T#是最终的标注结果,即概率最大的序列。则有:
W=(w1,w2,……,wm)
T=(t1,t2,……,tm),m>0
T#=arg max P(T|W)…………E1
根据贝叶斯公式有,P(T|W)=P(W|T)P(T)/P(W)…………E2
在基于 N-最短路径的统计粗分模型分析中可知,P(W)是一个常数,所以得
到:T#=arg max P(W|T)P(T)…………E3
如果把 wi 视为观察值,把角色 ti 视为状态值(t0 为初始状态)。那么可以把
这个问题看做一个隐马尔科夫模型(HMM)的问题:即已知观察观察序列 W,求状态序列T。对状态序列T 做一阶马尔科夫假设:ti 出现的概率只与ti-1 有关,
p(ti|t1,t2,……,ti-1)=p(ti|ti-1);假设当前的输出只与当前的状态有关,p(w1,w2,……wm|t1,t2,……,tm)=p(w1|t1)p(w2|t2)……p(wm|tm)。
综上所述:
T#=arg max P(W|T)P(T)
=arg max p(w<sub>1</sub>|t<sub>1</sub>)p(w<sub>2</sub>|t<sub>2</sub>)……p(w<sub>m</sub>|t<sub>m</sub>)p(t<sub>1</sub>|t<sub>0</sub>)p(t<sub>2</sub>|t<sub>1</sub>)……p(t<sub>m</sub>|t<sub>m-1)</sub>
=arg max _p_(_wi_ | _ti_) _p_(_ti_ | _ti_ 1) …………E4
为方便计算对 E4 取负对数:
T#=arg min( _i__m_1{ln _p_(_wi_ | _ti_) ln _p_(_ti_ | _ti_ 1)}) …………E5
用 viterbi 算法求解 E5 后,T#就求得了 从上述推导过程知,p(wi|ti)、p(ti|ti-1)是关键参数(p(wi|ti)是在给定角色 ti 的条件下,Token 是 wi 的概率;p(ti|ti-1)是角色 ti-1 到 ti 的转移概率),它们可以根据大数 定理求得: p(wi|ti)≈c(wi,ti)/c(ti);
c(wi,ti)是 wi 作为角色 ti 出现次数,c(ti)是角色 ti 出现的次数。
i>1 时,p(ti|ti-1)≈c(ti-1,ti)/c(ti-1)
c(ti-1,ti)是角色 ti-1 的下一个角色是 ti 出现的次数。
c(wi,ti)、c(ti)、c(ti-1,ti)都可以通过已经切分且标注好的熟语料库学习得到。
2.对角色U(人名的上文和姓成词)和V(人名的末字和下文成词)进行分裂处理
按U 的组成方式对其进行分裂(假设U 由pf 两个字构成):若f 为姓,则分裂为KB;若f 为双名首字,则分裂为KC;若f 为单名则分裂为KE。按V 的组成方式对其进行分裂(假设V 有tn 分裂为DL):若t 为双名末字,则分裂为DL;若t 为单名,则分裂为EL
3.模式串最大匹配实现
使用到的人名识别模式集为:{BBCD,BBE,BBZ,BCD,BE,BG,BXD,BZ,CD,FB,Y,XD}。一旦匹配到其中一个最长的模式串,则对应的Token 片段就识别为中国人民。例如:“馆/内/陈列/周/恩/来/和/邓/颖/超生/前/使用/过/的/物品”经过viterbi算法计算后,对应的T#为“AAKBCDMBCDLAAAAAA”。所以模式最大匹配后,识别得到的人名是:“周恩来”和“邓颖超”。
(二)、机构名的自动识别
机构名的识别和人名的识别类似,不同之处在于,机构名的构成更复杂且规律性更少(例如大多数机构有简称,机构名长度不定等)。从组成方式来看,完整的机构名可以分为前段和后端两部分。如“北京电视台”中“北京”为前段,“电视台”为后段。且机构名的上下文大多是一些连词、动词或者表示职务的名词等。如“主席”、“经理”。所以,根据这些特点,得到角色表如表二所示:
表二机构名角色表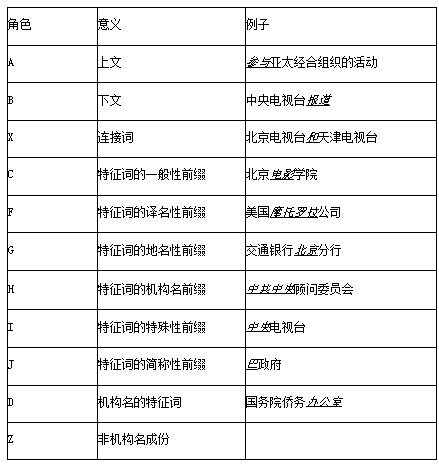
例如对切分结果:“在/1998 年/来临/之际/,/通过/中央/人民/广播/电台/向/全国/各族/人民/致以/诚挚/的/问候/和/良好/的/祝愿/!/”进行角色标注,得到的结果为:“在/Z1998 年/Z 来临/Z 之际/Z,/Z 通过/A 中央/I 人民/I 广播/C 电台/D向/Z 全国/Z 各族/Z 人民/Z 致以/Z 诚挚/Z 的/Z 问候/Z 和/Z 良好/Z 的/Z 祝愿/Z!/Z”。与人名识别类似,机构名通过viterbi 算法自动标注,再通过字符串比较找出满足[CFGHIJ]D 的子串,则机构名得以识别。
参考资料:
1、《基于角色标注的中国人名自动识别研究》
http://www.ictclas.org/ictclas_files.html
2、《基于角色标注的中文机构名识别》
http://www.ictclas.org/ictclas_files.html
3、有关HMM 的介绍:
http://blog.csdn.net/likelet/article/details/7056068
4、Viterbi 算法:
http://zh.wikipedia.org/wiki/%E7%BB%B4%E7%89%B9%E6%AF%94%E7
%AE%97%E6%B3%95