在上篇文章中对比了中文词语粗分的几个算法,提到N-最短路径算法在中文词语粗分中的优势,下面在这篇文章中就着重研究N-最短路径算法的原理。
首先我们要知道,N-最短路径算法中的N指的是什么?
_N指的是从源点到终点的前N条最短路径长度的若干条路径,这里有个地方要注意的是N指的是前N条最短路径长度。_例如:求2-最短路径,从源点到终点的最短路径长度为5,次短路径长度为6,但是包含最短路径长度的不一定就只有一条路径,譬如可能有两条路径A,B都是路径长度为5,又有三条路径C,D,E的长度为6,那么求2-最短路径即求A,B,C,D,E这五条路径。这个问题清楚之后,我们就开始下面的问题。
在了解N-最短路径之前,首先,我们来看看1-最短路径算法。顾名思义,1-最短路径即求的是最短路径,下面我们来看看1-最短路径是如何实现的:
一、数据表示
我们用如下的有向图来举例说明,各权重已标明:
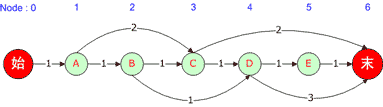
(图一)
根据有向图可以建立如下所示的二维表:
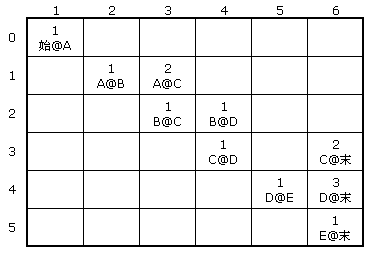
(图二)
二维表内取值即为权重。